Partial FSDat Indexes
Partial FSDat Indexes are used to speed up some FastStats queries for systems that have large transaction tables.
Every Multi-table FastStats system has a single master .FSDat file. This provides a map to the query engine of which table the records exist in. A record in a table contributes a single numeric record to the .FSDat file. As this .FSDat file increases in size then multi-queries will decrease in performance.
Not all multi-table queries require all the records in the .FSDat file. If you have the case of a large transaction table (for example Communications History) that is queried relatively infrequently then by generating a partial index you can speed up queries that do not require the transactional data.
Example
In this example a partial .FSDat file is created that contains all the tables apart from the Comms History table.
Consider a FastStats Demo System with additional Comms History Data. So the four main tables Households, People, Bookings, Insurances (~4m records) plus an additional large Comms History table (248m records).
The full FSDat file size for this system is 120 MB.
Create a Partial FSDat that excludes the Comms History by adding a Post-Load action like this:
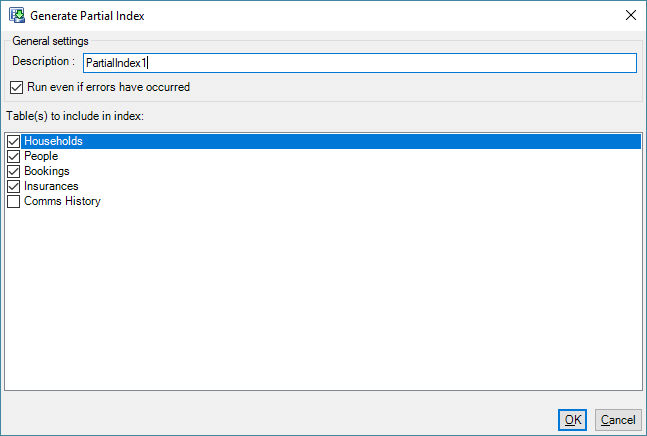
Adding this index increases the base system size by 2MB but it means that any multi-table query that does not involve the Comms History table will run faster since these queries will scan the 2MB partial index instead of the 120MB full index.
Recommendations
The partial index is generated with a filename that is the Post-load action description.
What Partial .fsDats should I create?
Create a partial .fsDat every time you have a big table in a separate relationship branch. So if the system above had another very large transaction table called Responses that join to the People table then create the following 3 partials FSDats for optimal query speeds:
Index1: Households, People, Bookings, Insurances
Index2: Households, People, Bookings, Insurances, Comms History
Index3: Households, People, Bookings, Insurances, Responses
Can Designer work out what I need automatically?
Not yet.
Should I create lots of Partial .fsDats?
There is a diminishing benefit as you create more small .fsDats No point giving the query engine a choice between a small index and a very small index.
Does it work with Distributed Processing?
Yes, and distributed processing will gain in the same way as sequential processing.